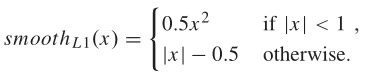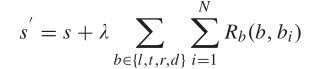|
车辆检测是主动驾驶车辆感知模块中的关头技能之一。因为视角、遮挡以及截断酿成的年夜规模内部门类的分歧,使患上车辆检测很是具备挑战性。本文提出基于多使命 CNN 以及 RoI 投票的车辆检测方式,优于年夜大都现有的车辆检测框架。 择要:车辆检测是主动驾驶体系中的一个具备挑战性的问题,由于其具备较年夜的布局以及外观变革。在本文中,咱们提出了一种基于多使命深度卷积神经网络(CNN)以及感乐趣区域(RoI)投票的新型车辆检测方案。在 CNN 系统布局的设计中,咱们以子种别、区域堆叠、鸿沟框回归以及每一个训练 ROI 的种别作为一个多使命学习框架来丰硕监视信息。该设计容许 CNN 模子同时在分歧车辆属性之间同享视觉信息,是以,可以有用地提高检测鲁棒性。别的,年夜大都现有方式自力斟酌每一个 RoI,疏忽了其相邻 RoI 的线索。在咱们的方式中,咱们哄骗 CNN 模子来展望每一个 RoI 鸿沟朝向响应标注过的数据的偏移标的目的。然后,每一个 RoI 可以对那些符合的相邻鸿沟框进行投票,这与该附加信息一致。投票成效与每一个 RoI 自己的患上分相连系,以从年夜量候选中找到更正确的位置。KITTI 以及 PASCAL2007 车辆数据集的试验成效讲明,与其他现有方式相比,咱们的方式在车辆检测中实现了卓着的机能。 1.弁言 车辆检测是许多视觉计较运用的根本问题,包含交通监控以及智能驾驶。不幸的是,因为分歧视点,遮挡以及截断引发的较年夜类内差别,车辆检测很是具备挑战性。图1显示了一些具备分歧繁杂性的例子,这些例子来自 PASCAL2007 汽车数据集 [1] 以及比来提出的 KITTI 车辆检测基准 [2]。
图 1.来自两个数据集的车辆检测的繁杂性的图示(a)PASCAL VOC2007 汽车数据集由分歧视点以及较少遮挡的单车构成。(b)KITTI 车辆基准包含安装在驾驶汽车上的摄像头拍摄的道路上的汽车,该汽车具备更多的遮挡以及截断。 凡是,车辆检测可以被视为通用对象检测的特殊主题。在曩昔几年中,研究职员在提高物体检测机能方面取患了光鲜明显进展 [3-8]。解决此问题的常见流程包含两个主要步骤:
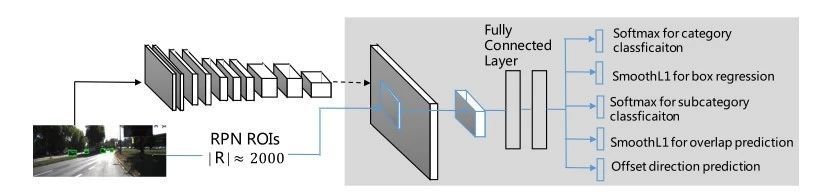
对付第一步,有不少精心设计的方式 [8-11] 用于天生建议方针或者仅仅是 [5] 中使用的滑动窗口方法。然后提取对象鸿沟框的一些特定视觉特性,并哄骗分类器肯定有界区域是不是指望对象,此中代表性方式包含 AdaBoost 算法 [3],DPM 模子 [5] 以及深度 CNN 模子 [7]。然而因为车辆的布局以及外观变革较年夜,尤为是广泛存在的遮挡,这进一步增长了类内差别,使患上车辆检测依然具备挑战性,别的,许多车辆检测基准要求联合交叉(IoU)跨越 0.7 以评估准确的定位,这显著提高了对模子的机能要求。 在本文中,咱们提出了一种基于多使命深度卷积神经网络(CNN)、感乐趣区域(RoI)投票以及多级定位的新型车辆检测方案,由 RV-CNN 暗示。多使命学习旨在实现信息同享,同时解决多个相干使命,提高部门乃至所有使命的机能 [12]。在咱们的方式中,CNN 模子在四个使命长进行训练:种别分类,鸿沟框回归,堆叠展望以及子种别分类。在这里,咱们引入子种别分类使命来使患上 CNN 模子在分歧的遮挡,截断以及视点下都能学习车辆的优秀暗示。咱们哄骗 [13] 中提出的 3D 体素模式(3DVP)观点进行子种别分类。3DVP 是一种对象暗示,它配合捕捉关头对象属性,这些属性触及到在聚类进程中刚性对象的外观、对象姿态、遮挡以及截断。然后每一个 3DVP 被认为是一个子种别。 年夜大都检测方式哄骗 CNN 模子的展望分数进行非极年夜值按捺(NMS),以获得终极的鸿沟框位置。可是,高于某一程度的检测分数与边框提案的靠得住性没有很强的相干性 [14]。缘由之一是训分类器被训练为从布景中对对象进行分类,而不是春联合交叉(IoU)进行排序。是以,咱们建议使用临近的 RoI 来完美这一评分。起首,咱们使用 CNN 模子同时展望从 RoI 到每一个鸿沟的标注过的数据的偏移标的目的。有了这些分外的信息,咱们设计了一个简略而有用的投票方案来从新分配这些 ROI。在所有提案的患上分从新计较后,咱们可以运用 NMS 获得终极成效别的,咱们察看到,在 IOU 跨越 0.7 的限定下,区域提案网络[8]的产出不克不及包管到达 100% 召回。这将对如下检测网络组成挑战,由于它必需在没有高质量建议的环境下处置一些坚苦的案例。别的,在更快的 R-CNN [8] 中,NMS 的展望框的检测分数不许确,由于它在回归以前运用了 RoI 的卷积特性。斟酌到这两个错误谬误,本文提出了一种多级定位方案,进一步提高了检测精度以及靠得住性。 咱们已经经在两个经常使用的车辆检测数据集(KITTI 车辆基准 [2] 以及 PASCAL VOC2007 汽车数据集 [1])上评估了咱们的方式。咱们的方式在 KITTI 车辆检测基准上实现了 91.67% 的 Ap,显著超出了比来的成效 [15-17]。别的,咱们还对 PASCAL VOC2007 汽车数据集进行了试验。试验成效讲明,与基线以及相干方式相比,咱们的 RV-CNN 模子具备了一致且光鲜明显的机能晋升。 2.相干事情 在本节中,咱们将扼要回首一下比来关于一般物体检测以及车辆检测的事情。 通用方针检测是比年来研究的一个活泼领域,有着年夜量的前期事情。[3] 中的级联式检测器是最先实现相对于高精度及时检测的方式之一。这类布局已经普遍用于实现人脸 [3],[18],行人 [19] 以及车辆 [20] 的滑动窗口探测器。基于部门的模子也是文献中最壮大的物体检测方式之一,此中可变形的组件模子(DPM)[5],[21] 是一个很好的例子。该方式采纳定向梯度直方图(HOG)特性作为输入,并哄骗由根滤波器以及组件滤波器构成的星形布局来暗示高度可变的物体,使其可以或许检测出被紧张遮挡的物体。 比来,深度卷积神经网络(CNN)浮现出了卓着的机能,在各类视觉使命中盘踞了最高精度基准 [22-26]。这些事情提出了年夜量的方式 [7],[8],[27-36] 解决了 CNN 模子的问题。在这些方式中,具备卷积神经网络(R-CNN)框架 [7] 的区域已经经取患了很好的检测机能,并成为对象检测的经常使用典范榜样。其根本步骤包含使用选择性搜刮的建议方针天生 [9],CNN 特性提取,基于 CNN 特性的对象候选分类以及回归。 然而 R-CNN 带来了过量的计较本钱,由于它为数千个建议方针重复提取 CNN 特性。为了加快 R-CNN 中的特性提取进程,提出了空间金字塔聚集网络(SPPnet)[28] 以及基于快速区域的卷积网络(Fast R-CNN)[29]。其错误谬误是依然采纳自下而上的建议方针天生,这是效率的瓶颈。相反,在 [8] 中提出了一种区域天生网络(RPN),它与检测网络同享全图象卷积特性,从而实现了几近无本钱的区域天生。MS-CNN [15] 由提议子网以及检测子网构成。在提议子网中,在多个输出层执行检测,以便匹配分歧标准的对象。这类方案也用于 SSD [32] 以及 TextBoxes [37]。另外一个有趣的事情是 YOLO [31],它在 7x7 网格内输出对象检测。该网络以 40fps 运行,但检测精度有所下降。 年夜大都这些深度模子都针对一般物体检测。为了更好地处置被遮挡车辆的检测问题,在 [38] 中的一个 DPM 模子提供的根以及组件分数设置装备摆设上使用了第二层前提随机场(CRF)。比来,在 [39] 以及 [40] 中提出了一个以及或者布局,以有用地将遮挡设置装备摆设与经典的 DPM 进行比力。在 [41] 中,作者建议将车辆检测以及属性注释连系起来。别的,改良模子泛化的一种常见方式是学习对象类 [20] 中的子种别。子种别已经被普遍运用于车辆检测,并提出了几种子种别分类方式 [42-45]。在 [42] 中,使用局部线性嵌入以及 HOG 特性以无监视的方法学习学习对应于车辆标的目的的视觉子种别。参考文献 [43] 凭据对象的视角执行聚类,以发明子种别。在 [45] 中研究了区别性质分类,此中聚类步骤斟酌了负面实例。比来,[13] 提出了一种新的对象暗示,即三维体素模式(3DVP),它配合编码对象的关头属性,包含外观、三维外形、视点、遮挡以及截断。该方式以数据驱动的方法发明 3DVPS,并为 3DVPS 训练一组专门的检测器。在 [46] 中,作者哄骗 3DVP 子种别信息训练子种别卷积层,输出特定位置以及比例下某些子种别存在的热图。在咱们的事情中,咱们将子种别分类作为改良基于 CNN 的检测机能的多使命的一部门,而且可使用在 [13]、[42] 以及 [43] 中得到的子种别标签来实现该组件。 3.详细检测进程 在本节中,咱们描写了用于解决车辆检测问题的多使命深度卷积神经网络。对付每一个输入图象,咱们的方式包含三个主要阶段。起首,咱们天生一个由多标准区域天生网络(RPN)[8] 得到的对象提议池。然后咱们使用多使命 CNN 模子来展望每一个 RoI 的属性。凭据回归成效,一些提案将由二级回归网络处置。末了,咱们采纳有用的投票机制来优化每一个 RoI 的终极患上分。别的,因为咱们可以得到子种别信息,是以咱们引入了子种别感知的非极年夜值按捺(NMS)来更好地处置遮挡。末了,咱们可以得到在现实运用中很是正确的展望框。 1 多使命丧失函数 比来,多使命学习已经经运用于许多计较机视觉问题,出格是在缺少训练样本的环境下 [12]。多使命学习的目的是在同时解决多个相干使命的同时,增强信息同享。这类同享已经经被证实可以提高部门或者全数使命的机能 [12],[47],[48]。对付车辆检测问题,咱们经由过程子种别,区域堆叠,鸿沟框回归以及每一个训练 RoI 的种别作为多使命学习框架,丰硕了监视信息。接下来,咱们将具体诠释多使命 CNN 模子的提议方式的细节。图 2 显示了所提出的多使命学习框架的整体流程。如图 2 所示,在天生 RoI 以后,咱们将 [29] 中提出的 RoI 池化层运用于每一个 RoI 的池卷积特性。然后,聚集的卷积特性用于完成四个使命:种别分类,鸿沟框回归,堆叠展望以及子种别分类。末了一部门「偏移标的目的展望」将在下一节中描写。每一个被训练的 RoI 都标有真实类以及真实鸿沟框回归方针,雷同于 [29] 中的设置。凡是,该监视信息用于设计分类丧失 L cat 以及鸿沟框回归丧失 L loc。 接下来,第三个使命是子种别分类。对付繁杂以及杂乱的都会场景中的车辆检测,遮挡以及视点是关头方面。如在 [40] 中,处置遮挡必要可以或许捕捉组件层面上遮挡的根本纪律(即分歧遮挡设置装备摆设),而且明确地哄骗与遮挡配合产生的上下文信息,这超越了单车辆检测的范畴。别的,分歧视图中的 2D 图象也难以辨认。这些光鲜明显增长了类内差别。为了暗示遮挡以及视点变革,咱们采纳比来在 [13] 中提出的 3D 体素模式(3DVP)的观点。3DVP 是一种对象暗示,它配合捕捉与外观,三维外形以及遮挡掩膜相干的关头对象属性。参考文献 [13] 提出在网络上的存储库中哄骗 3DCAD 模子,比方 Trimble3D Warehouse,并将这些 3D CAD 模子与 2D 图象一块儿标注以构建 3D 体素示例。更详细地说,对付训练集中的每一个图象,使用从预界说的模子纠合中选择的 3D CAD 模子来标识表记标帜图象中的对象,选择的模子是有与真实 3D 长方体最接近的纵横比的模子。然后使用相机参数将所有标注的 3D CAD 模子投影到图象平面上并得到深度排序掩模。在下文中,深度排序掩模肯定投影的 3D CAD 模子的哪一个像素是可见的,被遮挡的或者截断的。3DVP 暗示一组三维体素示例,这些示例同享在其三维体素模子中编码的雷同可见性模式。参考文献 [13] 经由过程在同一的三维空间中聚类三维体素样原本发明 3DVP。有关具体信息,读者可以参考他们的项目网站。
图2. 多使命框架的图示 在 [13] 以后,咱们对刚性物体(即 KITTI 中的车辆)采纳 3D 体素模式(3DVP)暗示,它在聚类进程中配合摹拟物体姿态,遮挡以及截断。然后每一个 3DVP 被认为是一个子种别。图 3 显示了 Kitti 车辆数据集中分歧子种别车辆的几个示例。经由过程这些附加的注释,CNN 模子可以捕捉更多关头信息进行检测。如图 2 所示,CNN 模子在 K + 1 个子种别上输出离散几率散布(每一个 RoI),p =(p 0,...,p K)。与往常同样,p 是由一个全毗连层的 k+1 个输出上的 softmax 计较的。是以,子种别分类的丧失公式为 Lsub(p,u) = logpu,它是真实分类 u 类的对数丧失。
图 3.每一一列为一个子分类 别的,咱们发明展望 RoI 与响应的标注过的数据之间的堆叠对其他使命是有利的。对付堆叠回归,咱们使用下列方程中的丧失。 此中
是一种壮大的 L1 消耗,其对异样值的敏感性低于 L2 消耗,这必要细心调整学习速度以避免爆炸梯度。Op 暗示由 CNN 模子展望的堆叠,而且凭据 ROI 以及标注过的数据计较 Og。 总结,整个多使命框架的丧失可以表述为: 上式中的超参数 λ1,λ2,λ3 用于节制四个使命丧失之间的均衡。咱们在验证数据集上调整了这些超参数。详细地,在试验中将 λ1,λ2,λ3 设定为 1,10,1.2。 2 感乐趣的区域投票 咱们察看到检测分数不克不及很好地暗示有界区域的靠得住性或者置信度。在 [14] 中,作者还认为,高于某一程度的检测分数与与框提议的最优性没有很年夜瓜葛。现实上这其实不奇异,由于分类器被训练为从布景中分类对象而不是对 IoU 进行排序。另外,展望框的分数由 RoI 的卷积特性计较,其与回归框略有分歧,这也是值患上思疑的。为领会决这个问题,咱们使用临近的 RoI 来优化其患上分。起首,咱们使用 CNN 模子同时展望从每一个 RoI 鸿沟到标注过的数据鸿沟的偏移标的目的。然后咱们可以获得四个变量来批示现实的标的目的。在咱们的方式中,咱们划分用 D l,D t,D r,D d 暗示这四个变量,划分用于 RoI 的左侧界,顶鸿沟,右侧界以及下鸿沟。比方,D l的可能展望以下:「向左转」,「向右转」,「在此处遏制」以及「此 RoI 周围没有实例」。对付 D t,「上升」,「降低」,「在此处遏制」以及「此 RoI 周围没有实例」是可能的训练标签。这些标签可以凭据 ROI 的位置以及训练前的地面实况来计较。 如前所述,咱们使用多标准 RPN 模子来天生数千个对象提议。哄骗所提出的多使命 CNN 框架,展望每一个 RoI 的鸿沟框偏移,患上分以及标的目的。然后连系每一个 ROI 的坐标以及响应的框偏移量,咱们可以获得年夜量的展望框,这比现实的图象中的物体数目年夜患上多。是以,咱们将一个图象中的所有展望框分成组,每一组对应一个对象。分组方案简略以下:咱们选择具备最高分数的展望框作为种子,并将具备高 IoU 的框与种子放入一个组中。此进程将迭代,直到分配了所有框。该方案在物体检测中很常见 [5],[7],[8],[29]。咱们的方针是为每一个组找到最好对象展望框。之前的方式直接选择具备最高展望分数的展望框。 在这里,咱们哄骗来自每一个展望框的相邻 RoI 的附加信息来优化分数。若是展望框的位置与其相邻 RoI 的展望标的目的一致,则该展望框更靠得住。不然,应削减展望框的终极患上分。为清楚起见,假如展望框具备坐标以及患上分 s。而且咱们用 B 暗示它的相邻 RoI,用 N 暗示 B 中 RoI 数目,用 si 暗示的第 i 个 RoI 的患上分,用暗示展望标的目的。然后咱们制订投票方案,以下所示:
此中
其他 r b(b,b i)函数遵循与 r l(b,b j)不异的划定规矩。在所有展望框的患上分从新计较后,咱们可以运用 NMS 获得终极的成效。 这类 RoI 投票方式有几个优点。起首,分歧于被训练以从布景中对对象进行分类而不是对 IoU 进行排名的种别分类器,咱们的 RoI 投票方式展望朝向标注过的数据的偏移标的目的,这对付位置是公道的。别的,该 RoI 投票方式哄骗来自相邻 RoI 的统计信息,这使患上成效加倍稳健以及靠得住。其次,与基于 CNN 的回归使命解决检测问题的方式相比,咱们的方式采纳了加倍文件的分类模子,既简略又有用。CNN 模子在分类使命上凡是比回归使命取患上更好的机能 [49]。因为具备 softmax 丧失的偏移标的目的的分类使患上模子在真实标的目的上最年夜限度地激活,而不是在鸿沟框坐标的切确值上激活。别的,展望朝向标注过的数据的标的目的可以作为多使命框架的一部门来实现,这不会给计较带来分外的包袱。 3 多级定位 在 Fast RCNN [29] 等常见的方针检测流程中,咱们发明了两个错误谬误。起首,因为许多检测基准要求 IOU 跨越 0.7 才气评估准确的定位,是以区域天生网络 [8] 常常没法到达 100% 的召回率。这将对如下检测网络组成挑战,由于它必需在没有高质量建议的环境下处置一些坚苦的案例。其次,在快速的 R-CNN 中,用于进行 NMS 的提案的分数不许确,由于它们在回归前采纳了特性。这两个身分将下降这些检测器在现实车辆检测使命中的机能。是以,咱们引入了一个多条理的定位框架,以粗到细的方法解决这两个问题。详细来讲,咱们的定位方案从区域天生网络 [8] 起头,经由过程迭代评分以及细化它们的坐标来事情。在这里,咱们施行了一个两阶段方案。起首,咱们将所有与标注过的数据堆叠年夜于 0.5 的提案作为培训第一阶段回归网络的正样本。因为咱们发明 RPN 在直接使用 0.7 时未能召回所有车辆,而在 0.5 时所有车辆都有正面建议。在测试阶段,该回归网络可以将召回率从 97.8% 提高到 98.9%。在第二阶段,咱们使用来自第一阶段的展望鸿沟框来训练第二级方针检测网络,使用与标注过的数据堆叠年夜于 0.7 的建议作为阳性样本。在这个阶段,年夜大都车辆都有高质量的建议,这使患上回归使命相对于容易。别的,咱们发明第一级网络的输出提供了强有力的建议,使第二网络发生更正确的定位。另外,由第二网络计较的鸿沟框偏移凡是很小,这使患上展望框的患上分更正确。
(a)原始图象(b)NMS 以前的部门车辆检测成效 斟酌到速率,咱们对所有提案进行一级定位,并选择此中的一部门进行二级定位。选择的划定规矩是:若是一个提案与展望框有很年夜的堆叠,咱们将不会进行第二次定位。咱们认为,若是堆叠度很年夜,评分是正确的,提案不必要再次回归。在试验部门,咱们将此阈值设置为 0.9。在多级定位以后,咱们得到了一系列检测成效,这些检测成效都具备高召回率以及正确定位。咱们斟酌重用卷积层功能来进行多级定位。可是,机能增益其实不使人得意。是以,对付第二阶段,咱们训练一个新的回归网络。咱们采纳这类设计是由于咱们但愿经由过程响应鸿沟框的卷积特性尽快正确地计较提案的分类分数。 4 子种别的NMS 在繁杂的交通场景中,遮挡使患上车辆检测很是具备挑战性。比方,图 4 中的蓝色圆圈中有两辆汽车彼此挨近,它们的 IOU 年夜于 0.7。尽管咱们以前的管道可以检测到它们的位置并为它们分配高分,但尺度的后处置步骤 NMS 将过滤此中一个分数较低的鸿沟框。若是咱们将 NMS 的阈值设置患上更高,则可以保存两个鸿沟框。 可是,检测成效的精度会很是低。为领会决这个难题,咱们引入了子种别的 NMS(subNMS)方式。在咱们的多使命框架中,咱们可以得到子种别信息。因为蓝色圆圈中的两辆车属于分歧的子种别,咱们的 subNMS 哄骗级联管道。起首,咱们为属于统一子种别的鸿沟框执行尺度 NMS,其严酷阈值为 0.5。然后,NMS 将处置所有鸿沟框,其阈值为 0.75。经由过程所提出的 subNMS,检测成效的切确度以及召回率可以到达均衡。 5 施行细节 咱们的框架是使用 caffe[50] 实现的,运行在设置装备摆设了 Nvidia M40 GPU 卡的事情站上。咱们不从零起头培训咱们的 RPN 以及检测 CNN,而是运用在 ImageNet [22] 上预训练的模子来初始化卷积层以及前两个全毗连层,然后对整个网络进行微调。在 KITTI 基准测试中,咱们对第一级定位的 AlexNet [22] 以及第二级定位的 GoogleNet [51] 进行了微调。 为领会决标准的变革,咱们使用多标准方法来训练第一级定位。因为 GPU 内存限定,咱们没法直接培训多标准 GoogleNet 检测网络。是以,咱们自力裁剪以及调整 RoI,不在统一输入图象中同享卷积计较。用于多使命学习的全毗连层划分由尺度差为 0.01 以及 0.001 的零均匀高斯散布初始化。误差初始化为 0。所有层对权重使用 1 的每一层学习率,对误差使用 2 的每一层学习率,全局学习率为 0.001。在对 KITTI 训练数据集进行训练时,咱们运行 SGD 进行 30k 小批量迭代,然后将学习率下降到 0.0001 并训练另外 10k 次迭代。学习在 40,000 次迭代后遏制,而且在学习时代,将 conv1-1 到 conv2-2 的层参数固定,以实现更快的训练。 在对 VOC07 trainval car 数据集进行训练时,咱们运行 SGD 进行 8K 小批量迭代,然后将学习率下降到 0.0001,再进行 2K 迭代培训。使用 0.9 的动量以及 0.0005 的参数衰减(基于权重以及误差)。 4.试验 在本节中,咱们在两个大众数据集上评估咱们的方式:KITTI 车辆检测基准 [2] 以及 PASCAL VOC2007 汽车数据集 [1]。 1 KITTI验证集的试验 KITTI 数据集由 7481 个训练图象以及 7518 个测试图象构成。训练中的物体总数到达 51867,此中汽车仅占 28742。KITTI 汽车检测使命的关头难点在于年夜量汽车尺寸较小(高度<40 像素)而且被遮挡。 因为 KITTI 测试集的根本真实注释不公然,咱们使用 [46] 的训练/验证朋分来对咱们的框架进行阐发,此中划分包括 3682 个图象以及 3799 个图象。对付 KITTI 的验证,咱们使用 125 个子种别(125 个 3DVP 用于汽车),而对付 KITTI 的测试,咱们使用 227 个子种别(227 个 3DVP 用于汽车)。关于子种别的数目,咱们遵循 [13] 中的设置装备摆设。3DVP 是一种数据驱动方式,子种别的数目是聚类算法中使用的一个超参数。对付验证数据集,仅使用训练数据集来发明 3DVP 模式。对付测试数据集,训练数据集以及验证数据集的连系加倍繁杂,以是子种别的数目更多。
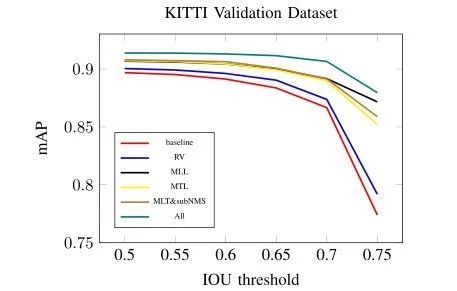
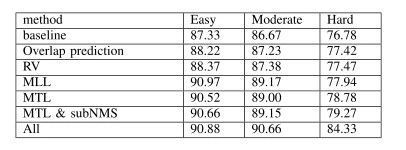
图 5 检测胜利以及失败案例示例(绿色框暗示正肯定位,赤色框暗示毛病报警蓝色框暗示检测缺失) 咱们凭据 KITTI 基准 [2] 建议,在三个难度级别(简略,适度以及难度)上评估咱们的辨认成效。为了评估物体检测精度,在整个试验中陈述均匀精度(AP)。 汽车的 KITTI 基准采纳 0.7 堆叠阈值。表 I 显示了三个种别的检测成效,此中咱们证实了各类组分对 KITTI 的 RV-CNN 机能的影响。从表 I 可以看出,多使命学习,RoI 投票以及多条理当地化的构成部门都是有用的设计。对付那些中等以及难度级此外汽车,咱们的方式可以经由过程更多组件实现更好的机能。
图 6.在 KITTI 验证集上的分歧 IOU 阈值下的 AP 曲线 表 1
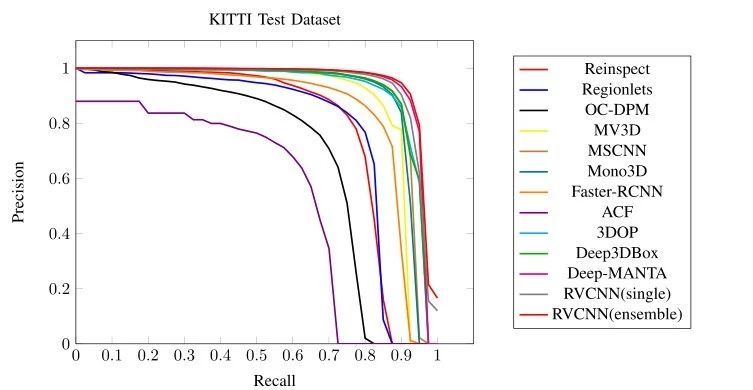
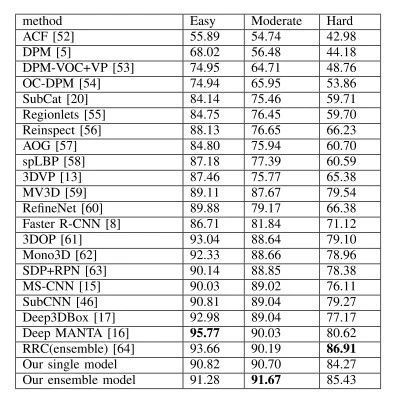
为了展现咱们方式的稳健性,咱们给出了图 6 中分歧 IOU 阈值下的 AP。别的,图 5 显示了咱们在 KITTI 验证数据集上的检测成效的一些示例。咱们可以看到,检测中失败的年夜可能是那些难以看到的被遮挡的汽车。未来,咱们必要将 CNN 模子与一些遮挡推理机制相连系,以更好地处置这些坚苦案例。 2 KITTI测试集的试验 为了与 KITTI 检测基准的最新方式进行比力,咱们使用所有 KITTI 训练数据训练咱们的 RPN 以及 RV-CNN,然后将咱们的成效提交到官方网站,在 KITTI 测试集上测试咱们的方式。 表 2 列出了三类检测成效,咱们将咱们的方式(RV-CNN)与 KITTI 评估的分歧方式进行了比力。这些成效是在 2017 年 3 月提取的。比来,评估剧本已经经更改,并提供了原始成效。咱们的方式在基于中等难度成效的所有已经发布方式中排名第一。试验成效证实了咱们的 CNN 可以或许处置具备更多遮挡以及截断的车辆。图 7 给出了中等种别的 KITTI 测试装配的切确召回曲线。
图 7.中等难度成效的 KITTI 测试集的切确召回曲线,没有方式描写的匿名提交将被疏忽 表 2
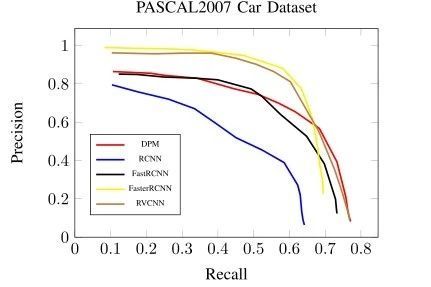
3 VOC Pascal 2007车辆数据集的试验 咱们还将咱们方式与几个竞争模子:DPM [5],RCNN [7],快速 RCNN [29] 以及更快的 RCNN [8] 在另外一个大众数据集长进行了比力:PASCAL VOC2007 汽车数据集 [1]。这些方式在一般物体检测方面得到了最早进的机能,而且这些代码是公然可用的。
图 8.PASCAL2007 汽车数据集上的切确召回曲线 咱们在 VOC-RELEASE5 [65] 中采纳训练好的车辆模子用于 DPM,而基于 CNN 的其他模子以及咱们的方式则基于预训练的 VGG16 模子。提取 PASCAL VOC 2007 数据集中的训练集以及测试集(统共 1434 个图象)中包括的所有图象以进行评估。 汽车检测评估尺度与 PASCAL 方针检测不异。联合交叉(IoU)设置为 0.7 以确保定位准确。图 8 显示了 PASCAL VOC2007 汽车测试集的切确召回曲线。因为 3DVP 必要标注过的数据 3D 注释(立方体)以及相机参数,咱们没有找到 PASCAL VOC 的这些标签。是以,咱们删除了了 PascalVOC 数据集试验中的子种别分类使命。APS 划分为 63.91%(咱们的模子)、38.52%(RCNN)、52.95%(快速RCNN)、59.82%(快速 RCNN)以及 57.14%(DPM)。虽然这个数据很是小,但咱们的方式照旧赛过了其他方式。 5.结论 在本文中,咱们开发了一种基于多使命深度卷积神经网络(CNN)以及感乐趣区域(RoI)投票的新型车辆检测方案。KITTI 以及 PASCAL2007 汽车数据集的试验成效讲明,咱们的方式优于年夜大都现有的车辆检测框架。在将来,咱们将索求一个更有用的投票机制的端到端框架。别的,咱们但愿将 CNN 模子与一些遮挡推理方式相连系,以更好地处置这些坚苦案例。 来历:同济智能汽车研究所感知前沿研究组 原文:Multi-Task Vehicle Detection With Region-of-Interest Voting 链接:https://ieeexplore.ieee.org/document/8066331/ 编纂:小二 入群:加微旌旗灯号 autoHS,入厚势汽车科技群与行业专家计议更多主动驾驶行业信息 厚 势 汽 车 点击浏览原文,查看文章「华为的自我救赎以及主动驾驶的战国期间」 |